Bisnis.com, JAKARTA - Film kartun dan animasi adalah salah satu genre hiburan yang cukup populer. Salah satu perbedaan dibandingkan dengan film biasa adalah pada cara para tokohnya bersuara.
Tokoh dalam film kartun tentunya tidak benar-benar berbicara. Di belakangnya, ada aktor yang menyuarakan percakapan, sehingga para penonton mendapat kesan bahwa tokoh kartun itu benar-benar hidup dan berbincang-bincang seperti manusia.
Untuk mendapatkan kesan ini, para animator biasanya harus menyesuaikan gerakan bibir tokoh yang digambarnya agar sesuai dengan percakapan.
Ini mungkin tidak masalah bagi film animasi biasa, karena penyesuaian ini bisa dilakukan di studio animasi lebih dahulu, sebelum diputar di bioskop. Namun, bagaimana misalnya bila Anda ingin menghadirkan tokoh kartun dalam siaran langsung di televisi?
Di Amerika Serikat, pembawa acara bincang-bincang sudah beberapa kali menghadirkan tokoh kartun dan seolah-olah mewawancarainya.
Pada kesempatan ini, para aktor suara mengendalikan tokoh kartun tersebut ketika berinteraksi baik dengan aktor lain, pembawa acara, atau bahkan penonton.
Sebab, animator tidak dapat mengetahui kata-kata yang diucapkan oleh para aktor, mereka tidak bisa melakukan lip sync (penyelarasan bibir) manual seperti yang mungkin dilakukan pada film animasi.
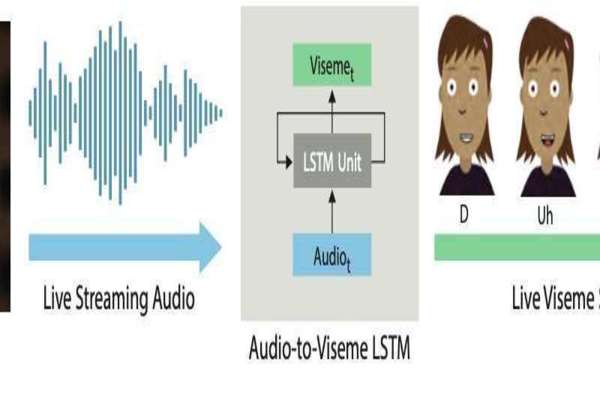
Acara seperti ini harus bisa menampilkan animasi tokoh kartun secara langsung (live), termasuk sinkronisasi antara kata-kata dan bibir tokoh dalam gambar hidup tersebut.
Wilmot Li dari Adobe Research dan Deepali Aneja dari Universitas Washington, Amerika Serikat berusaha menerapkan teknik jaringan saraf tiruan untuk menghasilkan penyelarasan bibir langsung yang lebih baik.
Li dan Aneja menggunakan model LSTM (long short-term memory), arsitektur RNN (recurent neural network) yang sebelumnya sering digunakan untuk pengolahan dan klasifikasi data, serta melakukan peramalan.
Pada dasarnya, penerapan jaringan saraf tiruan pada sinkronisasi bibir untuk animasi ini masih ada kaitannya dengan analisis pengenalan suara (speech recognition). Namun, ada beberapa perbedaan.
Pertama, lip sync langsung untuk animasi ini menuntut waktu pemrosesan yang lebih cepat tanpa waktu tunda atau latensi.
Kedua, berbeda dengan pengenalan suara yang memetakan pengucapan manusia ke cukup banyak fonem (biasanya lebih dari 20), lip sync untuk animasi ini biasanya hanya membutuhkan pemetaan ke belasan gambar bentuk bibir.
Untuk menguji kualitas implementasi teknik mereka, Li dan Aneja melakukan pengujian dengan responden, yang membandingkan hasil teknik baru ini dengan hasil produk komersial yang sudah ada.
Untuk tiap rekaman, dua peneliti ini mengumpulkan 20 penilaian dari responden yang disewa dari Amazon Mechanical Turk.
Hasilnya, tanggapan para responden terhadap teknik berbasis jaringan saraf tiruan ini lebih baik dibandingkan tanggapan terhadap hasil produk komersial.
Karena penelitian Li dan Aneja ini menunjukkan hasil yang cukup baik, Adobe memutuskan untuk mengintegrasikannya dalam produk Adobe Character Animator pada 2018.
Laporan hasil penelitian Li dan Aneja yang berjudul Real-Time Lip Sync for Live 2D Animation, yang diunggah pada tanggal 19 Oktober 2019, dapat dibaca di situs arxiv.org.














